一、写在前面
每年都会看看大神们的一年工作总结,感叹一番,从来没有自己的工作总结,现在毕业5~6年,还没有成家立业,有点迷茫,总结一下自己的工作,也算是生涯的一个记录,作为一个非CS专业人士,在学院路技校毕业时啥也不会,就是觉得未来云存储这个方向肯定不错,于是17年毕业后来到中科曙光加入了ParaStor300的团队,负责内核私有客户端的相关工作,非常感谢这份工作让我对分布式系统有了不错的了解,这里有的领导很好,比如为人师长的苗老师,最重要的是有幸在这里认识了一些朋友,不过也有糟心事,在曙光工作1年9个月后,从2019开始来到百度到现在整四年时间从事分布式存储系统BaikalDB的研发工作,在这里真的是学到了很多,虽然和同龄人比技术还是落下了,但是有幸沾团队的光,有一些技术积累,下面就重点review下一下重点工作内容。
二、主要工作
2.1 工作内容
BaikalDB是一个分布式的NewSQL系统,关于BaikalDB这个项目我们团队的leader发布的文章《面向大规模商业系统的数据库设计和实践》作了非常详细的介绍。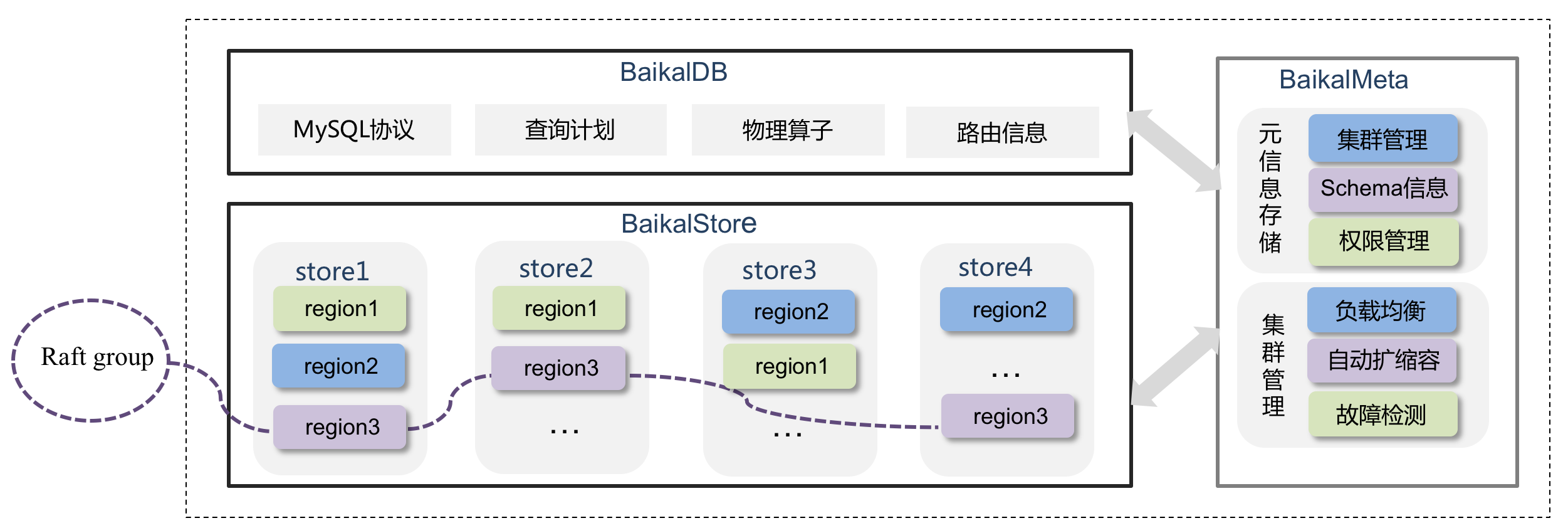
到2022年底我们完成了部门最大的MySQL集群(32分片,1主12从)迁移到BaikalDB的工作,数千类SQL,日均数十亿级PV,项目完成阶段性目标。有幸经历了整个项目的发展历程,下面简单回顾下自己做了哪些工作:
- 分布式事务:BaikalDB通过2PC,借助RocksDB单机悲观事务和Savepoint机制,把raft日志作为redo log实现分布式事务,更多细节在我之前发布的《BaikalDB分布式事务实现》一文中有介绍,当然这篇文章有些内容已经过时了,大体原理还是没变。我们还没有实现MVCC,所以会有Partial Read的问题,这是很大的缺陷;
- 全局索引:主表和索引表在不同region,用分布式事务保证数据一致;
- Binlog部分工作:TSO,Binlog数据的交互,用分布式事务保证普通表和binlog存储的数据一致;
- online DDL:和业界一样也是参考F1的Online Schema Change论文;
- 支持MySQL prepared statements、分区表PARTITION,简单的子查询;
- 引入HyperLogLog、BITMAP、Tdigest类型支持大数据量的分析;
- 性能调优,OOM,…
在没啥社区活跃度的前提下见证BaikalDB到1k的Star,还是相信自己的工作是很有价值的,BaikalDB的主要版本发布功能介绍:
2.2 一些case
- 一条insert SQL有2~3个G;
- 单表万亿级数据;
- 百万级region管理;
- 一行数据中一个字段就超过16M(16M是MySQL单个包的大小);
- 一个事务几千个sql很常见;
- raft有false negitive,日志commit时leader的日志可能还没有落盘;
- raft learner获取使数据用pull还是push;
- 读请求得有backup_request;
- 非幂等的请求处理在需要返回数据到db时store需要缓存response;
- 网络问题请求可能乱序执行;
- 分布式系统幂等,ABA,网络超时等问题处理要时刻留意;
- …
- 最后,自己没写过几条业务sql,开发数据库感觉挺不可思议的。
三、未来
能在业务部门四五个人一起完成一个分布式数据库的研发是很难的,数据库是一个非常有意思的领域,查询引擎、存储引擎、优化器等都很有挑战,希望自己能够继续深根,成为一个数据库专业人士。如果你使用的是C++又对分布式数据库感兴趣,那BaikalDB是值得研究一下的,欢迎交流。
分布式系统领域现在计算和存储分离,元数据和数据分离,分布式存储元数据用分布式数据库或者分布式KV,数据存入对象存储系统,用加速层来满足性能需求,像JindoFS,JuiceFS,分布式数据库计算和存储分离,计算层,log层,存储层,像最早的Aurora,到Socrates/AlloyDB,现在的云上存储的玩法很多,只叹自己水平有限,属于编码能力不足的程序员。