Google GFS文件系统是一个面向大规模数据密集型应用的、可伸缩的分布式文件系统。构建在廉价的PC机上,具备良好的容灾能力和性能。
1. Introduction
- 分布式系统中错误是常态,所以需要有持续的监控、错误侦测、灾难冗余以及自动恢复的机制
- 文件普遍较大,达到GB级别,需要重新考虑I/O操作和block大小
- 大部分的文件是追加写而不是覆盖写,一旦写完通常是顺序读取,缓存数据块对性能提升不明显,数据的追加操作是性能优化和原子性保证的主要考量因素。
2. Design Overview
2.1 设计的考量
- 系统由许多廉价的普通组件组成,组件失效是一种常态
- 面向大文件设计,典型文件大小在100MB以上。支持小文件但不做专门优化
- 主要有两种读模式,大块顺序读和小块随机读。应用可以将多个随机读合并排序,然后顺序读取提升性能
- 写模式为大块的顺序追加写入,也支持小块的随机写入,但性能较差
- 支持多客户端高效的并发追加写同一个文件
- 高吞吐优先于低延时
2.2 Interface
- 提供create、delete、open、close、read、write接口
- 支持snapshot和record append
2.3 Architecture
一个GFS集群由一个Master节点和若干个ChunkServer节点组成,Master节点通过多副本保证高可用。
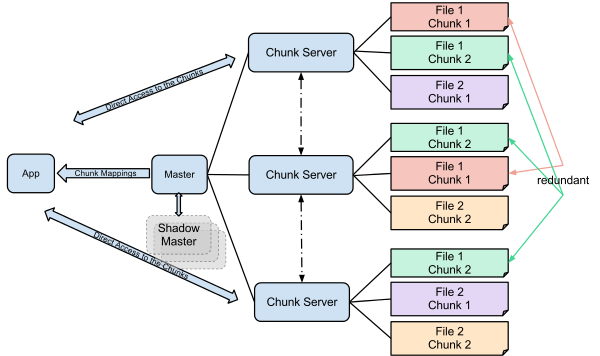
Master的职责:
- 维护所有metadata,包括namespace、ACL、file到chunk的映射、chunk的路由信息
- 负责lease管理,chunk副本管理,负载均衡,chunk的GC
- master和chunkserver周期性的heartbeat交互
client读写数据直接和chunkserver交互,只在需要metadata时于master通信,client和chunkserver都不需要自己缓存数据,这是由GFS的工作负载决定的,客户端缓存元数据,chunkserver利用Linux的page cache。
2.4 Single Master
单一的Master节点大大简化了设计,集中式的元数据管理方便定位chunk位置已经作出决策,同时集中式的master可能成为系统的瓶颈,client只在第一次访问一个chunk时向master发请求,并缓存这一信息,之后除非缓存的信息过期或者文件被重新打开,与该chunk的数据读写直接与对应的chunkserver交互。
Chunk Size
GFS的chunk size默认为64MB,远远大于一般文件系统的Block size,大的chunk size的优点:
- 减少了client和Master节点通讯的次数
- client在一个chunk上会进行多次操作,保存TCP长连接来减少网络开销
- 减少了master要维护的metadata
采用较大的chunk缺点是小文件可能成为热点,因为小文件在一个chunk内,这个chunk同时被很多的客户端读取时就成为热点,可以通过增加副本来解决。
2.6 Metadata
metadata包括:文件和Chunk的namespace、文件和Chunk的对应关系、每个Chunk副本的存放地点。
所有的元数据都会加载到master的内存中,namespace与文件和Chunk的对应关系会记录operation log到日志文件同时复制给master备份节点。同时master不会持久化chunk的位置信息,而是通过与chunkserver的心跳请求进行收集和维护。
2.6.1 In-Memory Data Structures
元数据全在内存中,所以Master服务器的操作速度非常快,Master定期扫描全部信息用于实现Chunk垃圾回收、Chunk副本修复、Chunk的迁移实现负载均衡。
同时master的内存大小也成为了整个集群服务数据规模的限制。
2.6.2 Chunk Locations
master而不持久化chunk的位置信息,而是通过与chunkserver的心跳来获取,原因:
- master的信息相比chunkserver是滞后的,持久化需要保持master与chunkserver数据的一致,考虑到chunkserver的扩缩容、failover、改名等情况,增加了复杂性。
- chunkserver上的chunk信息才是最新的
持久化这些信息对维护整个系统的也是有帮助的,可以加速集群的恢复。
2.6.3 Operation Log
操作日志包含了关键的元数据变更历史记录,也充当一个逻辑时钟,所有的master按照日志顺序进行apply。
Master服务器在日志增长到一定量时对系统状态做一次Checkpoint,在灾难恢复的时候,Master服务器就通过从磁盘上读取这个Checkpoint文件,以及重演Checkpoint之后的有限个日志文件就能够恢复系统。
Checkpoint文件以压缩B-树形势的数据结构存储,可以直接映射到内存。
2.7 Consistency Model
GFS不是强一致性模型
2.7.1 Guarantees by GFS
- 元数据的修改通过锁保证原子性和正确性
- 文件的region如果所有client无论从哪个replica看到的都是相同的数据,称其为一致的(consistent);如果一个region是一致的,同时client知道自己写入的数据,称其为确定的(defined)。
- 成功的串行写入是确定的,成功的并行写入是一致但不确定的,失败的写入是不一致的
- 成功的Record Append是确定的,同时有部分不一致
- 数据修改操作分为write和Record Append,write把数据写在应用程序指定的文件偏移位置上,record append保证把数据原子性的追加到文件中一次(atomically at least once),由GFS决定追加数据的offset
- GFS通过让所有replica应用相同的修改顺序和使用chunk version来标识过期replica保证数据
- 由于Chunk位置信息会被客户端缓存,所以在信息更新前,客户端有可能向一个失效的副本发送请求,chunk version就是处理这种情况
- 使用Checksum来校验数据是否损坏,损坏的replica会尽快进行修复,一般是几分钟之内检测到损坏副本,如果这几分钟内所有副本都损坏了,数据也会丢失
2.7.2 Implications for Applications
- 依赖追加写而不是覆盖写,通过原子的rename一个文件一个持久的名字或定期checkpoints从而知道哪些数据是确定的
- GFS读不是强一致,读的时候只读到最新的checkpoint,这些region肯定是已定义的
- 追加写比随机写效率高,同时处理失败也更具弹性
- Checkpoint可以让Writer以增量的方式重新开始,同时可以防止Reader处理已经被GFS成功写入,但是从应用程序的角度来看还并未完成的数据
- 数据可以自检验、自识别,通过checksum活着唯一标识可以知道哪些记录是无效的或重复的
3. System Interactions
系统交互的目标之一是最小化master对读写对影响。
3.1 Leases and Mutation Order
- master会为每个chunk挑选一个primary,primary负责决定这个chunk的所有修改的顺序,primary通过lease维护自己的地位。
- 租约机制减小Master节点的管理负担,默认60s,lease通过心跳进行续约,master可以主动取消lease(通常是需要修改元数据),master与primary chunk失联后,需要等lease过期后再挑选新的primary
client写操作流程: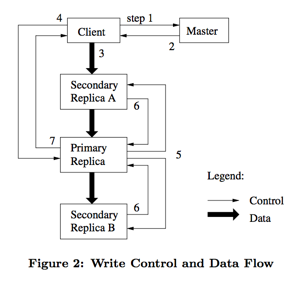
- client向master查询待写入chunk的副本信息,如果chunk没有primary,master选择一个授予lease;
- master返回副本信息并缓存,之后的读写都以这个信息为准,除非primary不能访问或lease过期;
- client将数据发送到所有的副本,此时数据只是写入到chunkserver的LRU buffer里不落盘,这里副本间数据是链式复制的方式,如今更多的是并行复制;
- client向primary发起sync请求,primary会给相应的数据赋值一个递增的序列号;
- primary将本地数据按照序列号顺序落盘的同时通知其他副本也将数据按照相同顺序落盘;
- 所有副本sync请求返回说明写入完成;
- primary返回client写入结果。
如果一次写入的数据量很大,或者数据跨越了多个Chunk,GFS会把它们分成多个写操作。
3.2 Data Flow
为了充分利用整个集群的网络带宽,将数据流和控制流分开来,同时可以根据网络拓扑优化数据流链式复制,每个chunkserver会把数据发送给离自己最近的还没收到数据的chunkserver。
chunkserver的距离GFS做的了通过IP地址直接估算。
3.3 Atomic Record Appends
正常的写入是由client指定offset,在多client并发写入时client的数据会交错,GFS提供原子的record append操作,
primary接收到一个atomic append请求时,它先判断当前chunk是否有足够空间,如果没有的话,它会先补全当前chunk,再返回client一个可重试的错误。否则primary先在本地追加,再告诉secondary具体的offset,最后回复client。
如果任一副本写失败,整个请求就失败了,client重试可能导致不同repilca不完全一致:每个replica上可能写了一次或多次或不完整的记录。GFS不保证每个replica完全一致,它只保证数据至少被原子写入一次。成功的请求表明数据一定在所有replica上写到了相同的offset上;每个replica的数据长度都至少等于这条记录的结束位置,因此任何后续的记录都会写到更高的offset或新chunk上(不会覆盖老数据)。
3.4 Snapshot
GFS使用COW技术实现Snapshot。
当GFS的Master节点收到Snapshot请求时:
- 回收Snapshot请求覆盖的文件chunks上的租约,这样,接下来客户端要对文件修改时,就必须向Master申请,而此时master就可以对chunk进行复制;
- Master在日志中记录本次Snapshot操作,然后在内存中执行Snapshot动作,具体是将被Snapshot的文件或目录的元数据复制一份,被复制出的文件与原始文件指向相同的chunk;
- 假如客户端申请更新被Snapshot的文件内容,那么找到需要更新的Chunk,向其多个副本发送拷贝命令,在其本地创建出Chunk的副本Chunk’,之所以本地创建是因为可以避免跨节点之间的数据拷贝,节省网络带宽;
- 客户端收到Master的响应后,表示该Chunk已经COW结束,接下来客户端的更新流程与正常的没有区别。
4. MASTER OPERATION
master负责所有文件元数据操作,此外还负责数据placement,chunk创建,负载均衡,副本修复,GC等。
4.1 Namespace Management and Locking
GFS没有使用树状结构维护namespace,逻辑上采用了kv表来表示,key是文件全路径,value是元数据。每个kv记录都有一个读写锁,访问一个路径时,必须持有路径前缀的读锁,再根据具体操作类型获取当前记录的读锁或写锁。这个锁机制允许并发操作相同目录,比如在同一个目录中并发创建文件,只需要获取前缀目录的读锁,而获取每个文件的写锁,获取目录的读锁防止目录被delete、rename、snapshoot。文件的写锁保证创建同名文件是互斥的。读写锁按需分配,加锁严格按照目录层次顺序,在同一目录内按照字符序。
4.2 Replica Placement
chunk副本必须合理布局保证scalability, reliability,availability。布局策略的目标:
- 最大化数据可靠性和可用性
- 最大化网络带宽利用率
常见的要求要保证同一个chunk副本分布在不同的机器,不同的rack,甚至是不同的网段,不同的交换机,不同的机房。
4.3 Creation, Re-replication, Rebalancing
chunk副本被创建的原因包括chunk creation,re-replication和rebalancing。
新建chunk副本考虑:
- 磁盘空闲的chunkserver
- 每个chunkserver最新创建的chunk不能过多,避免后续流量集中在这个chunkserver
- 分散在不同rack
master发现某个chunk正常的副本数少于配置的个数时就会触发re-replication,不同的场景有不同的优先级,优先考虑正常副本个数少的,chunk是否活跃,是否阻塞了client请求。同时要控制每个机器同时进行副本复制的个数,因为网络和IO是有限的。
master还会周期性地对副本进行Rebalance,以便网络带宽和IO分布均衡。
4.4 垃圾回收
GFS文件是延迟删除的,删除时master将删除操作记录到日志,将文件rename为一个包含删除时间戳的隐藏文件,之后定期扫描这些文件,超过配置期限的文件会被真正删除,即实现了TTL功能。chunkserver在心态信息中会带上它的chunk子集,master会判断这个chunk子集是否还有效,无效的chunk副本会通知chunkserver删除。
延迟删除为意外的删除提供恢复的可能,删除可以在空闲的时候进行,分散开销,但延迟删除使空间不能及时回收,应用程序平凡创建和删除文件的场景下空间资源浪费,GFS通过显式的再次删除一个已经被删除的文件的方式加速空间回收的速度,同时允许用户为命名空间的不同部分设定不同的复制和回收策略,用户可以指定某些目录树下面的文件不做复制,删除文件会立即删除。
4.5 Stale Replica Detection
master为每个chunk维护了vserion,每次授予lease时增加,version会被master和chunkserver持久化,通过比较version判断chunk副本是否stale,版本高的更新,即基于version的fence机制。
5. Fault Tolerance and Diagnosis
5.1 High Availability
组件频繁故障是最大的挑战,GFS通过两个有效策略提供高可用:fast recovery和replication
- Fast Recovery:master和chunkserver被设计为重启可以在数秒内恢复状态并提供服务
- Chunk Replication:chunk默认三副本,在有副本下线、数据损坏等情况时master会复制新的完整副本,也在考虑EC编码降低存储成本
- Master Replication:master的修改要等到operation log在所有副本上落盘才算提交成功,同时提供了shadow replica分担元数据读压力,即learner角色。
5.2 Data Integrity
- 使用checksum来校验chunk正确性,每个64K的block都会计算一个32bit的checksum到log中落盘并常驻内存
- 读的时候会验证checksum保证错误数据不会返回给client或者其他chunkserver
- 追加写的时候直接基于旧的checksum计算新的checksum,覆盖写需要读第一个和最后一个block重新计算checksum
- chunkserver在空闲时会自动进行checksum校验
更多资料: