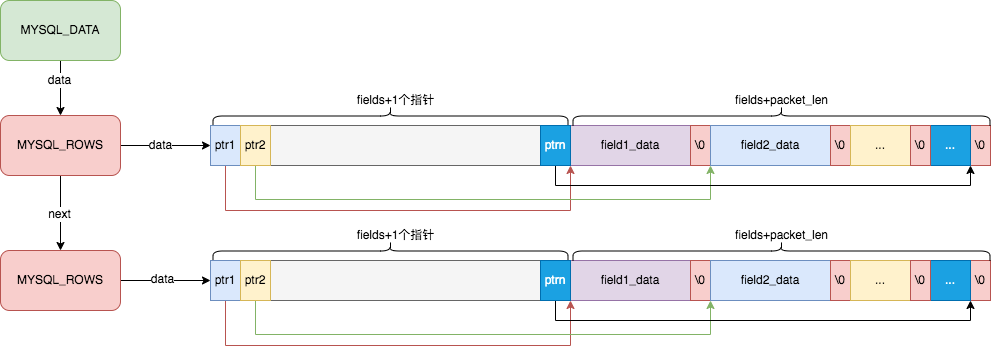
MySQL
每年都会看看大神们的一年工作总结,感叹一番,从来没有自己的工作总结,现在毕业5~6年,还没有成家立业,有点迷茫,总结一下自己的工作,也算是生涯的一个记录,作为一个非CS专业人士,在学院路技校毕业时啥也不会,就是觉得未来云存储这个方向肯定不错,于是17年毕业后来到中科曙光加入了ParaStor300的团队,负责内核私有客户端的相关工作,非常感谢这份工作让我对分布式系统有了不错的了解,这里有的领导很好,比如为人师长的苗老师,最重要的是有幸在这里认识了一些朋友,不过也有糟心事,在曙光工作1年9个月后,从2019开始来到百度到现在整四年时间从事分布式存储系统BaikalDB的研发工作,在这里真的是学到了很多,虽然和同龄人比技术还是落下了,但是有幸沾团队的光,有一些技术积累,下面就重点review下一下重点工作内容。
BaikalDB是一个分布式的NewSQL系统,关于BaikalDB这个项目我们团队的leader发布的文章《面向大规模商业系统的数据库设计和实践》作了非常详细的介绍。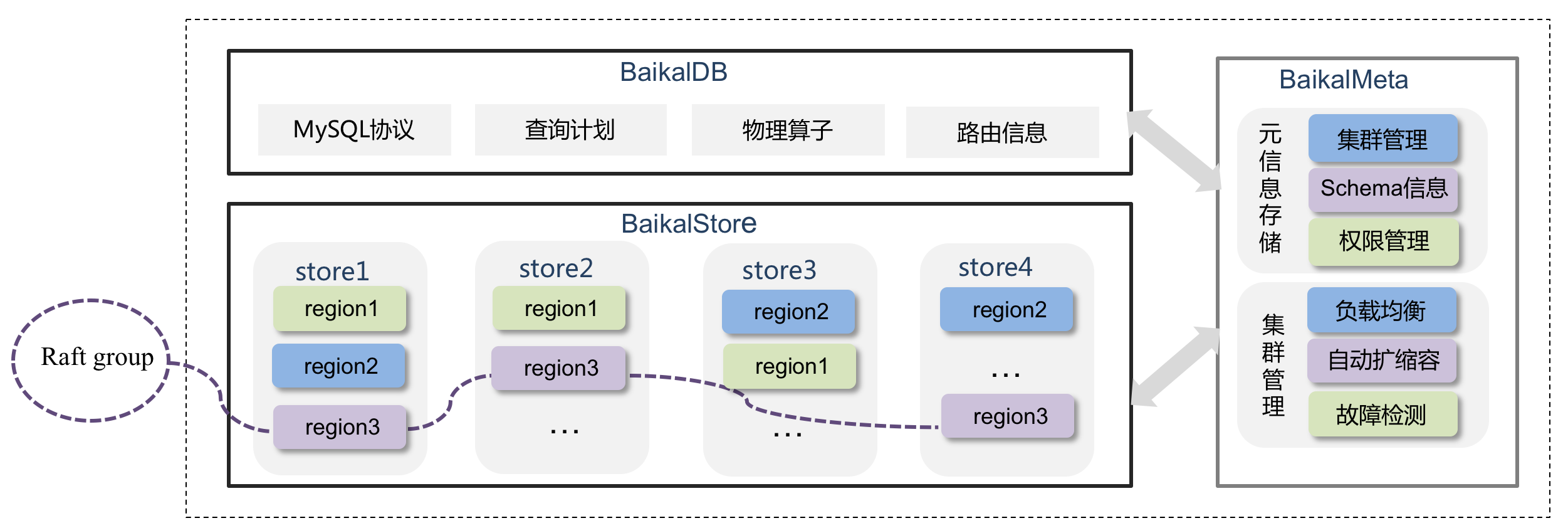
RUM Conjecture非常类似CAP theorem,指对于一个存储系统,出读(Read)、写(Updates)以及空间(Memory)三者之间是一个相互制约的关系,如图

snapshot是raft算法的四大特性之Log Compaction。
snapshot的主要作用,对本节点来说:
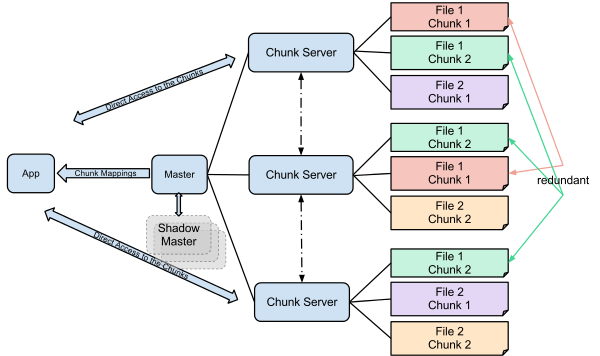
Google GFS文件系统是一个面向大规模数据密集型应用的、可伸缩的分布式文件系统。构建在廉价的PC机上,具备良好的容灾能力和性能。
一个GFS集群由一个Master节点和若干个ChunkServer节点组成,Master节点通过多副本保证高可用。
dynamic_cast提供类型安全检查,类型之间转换如果不兼容返回null,有时候我们需要在运行时判断一个对象的多态类型,就可以使用dynamic_cast,与Java的instanceof一样,被叫做Capability Query。
多态类型之间的转换包括:
测试同事在进行vdbench测试出现长时间断流,别的同事没有找到原因,问题最终来到我这里,jira记录没有做故障,后端服务进程正常。
现场没有了,还好保存了crash core,需要分析crash来定位。
1. 加载我们的内核模块 1crash> mod -S .
2. 打印所有进程栈信息,查看可疑的进程栈
|
|
使用read命令循环读取文件,按行进行处理时经常用到read命令:1234while read line; do echo $linedone < filename
这样做要保证filename文件的内容在读取的时候不会变化,否则可能会与你的处理逻辑不符合,比如
|
|
上述简陋的脚本想umount当前挂载的nfs客户端,但是如果有多个nfs挂载,会漏掉一些,这是因为在umount结束后
/etc/mtab文件也变了,umount的nfs相应的行没了,read按上一次记录的行继续读就出现了问题。
所以这样按行读要确保读的文件至少中间的行不要变化,简单的规避方法是cat filename | while read的方式,但这样
最好filename文件不大,不然很耗内存还可能overflow。
Linux的proc文件系统提供了很多进程内存使用情况的信息,详细请参考[1][2]
The /proc/PID/maps file containing the currently mapped memory regions and their access permissions.
maps文件的格式为:12345678910111213address perms offset dev inode pathname08048000-08049000 r-xp 00000000 03:00 8312 /opt/test08049000-0804a000 rw-p 00001000 03:00 8312 /opt/test0804a000-0806b000 rw-p 00000000 00:00 0 [heap]a7cb1000-a7cb2000 ---p 00000000 00:00 0a7cb2000-a7eb2000 rw-p 00000000 00:00 0a7eb2000-a7eb3000 ---p 00000000 00:00 0a7eb3000-a7ed5000 rw-p 00000000 00:00 0......aff35000-aff4a000 rw-p 00000000 00:00 0 [stack]ffffb000-ffffd000 r-xp 00000000 00:00 0 [vdso]ffffe000-fffff000 r-xp 00000000 00:00 0 [vsyscall]
You might notice a lot of anonymous regions. These are usually created by mmap but are not attached to any file. They are used for a lot of miscellaneous things like shared memory or buffers not allocated on the heap. For instance, I think the pthread library uses anonymous mapped regions as stacks for new threads.[4]